{kind=link}
General Information
You can get the latest implementation of my player under "My deliverables", on the left hand side of the screen. Be aware of the fact that the learning process is computationally expensive, and that the better the player plays, the longer your pc will be seized in a frenzy of learning join. When I say seized, I mean paralytic with joy, where the emphasis is on the term paralytic. The author accepts no responsibility for any repercussions following the running of this program.
Results
I have successfully achieved learning in a well of dimensions 4*20, when using reduced tetrominos. Tabular reinforcement learning methods are employed through the use severe reductions to the Tetris state space.
There are 2 distinct agents :
I implemented a TD(0) agent and a Sarsa(lambda) agent
The TD agent progresses from completing around 50 rows per game, to an average of 100 000 rows per game, with highs of .100 000 rows. This agent did not perform as well as the results indicate, and this is discussed my honours thesis available for download in the left sidebar.
The Sarsa player steadily improves until it completes around the 70 games. It then stumbles onto a policy which prolongs life, enough to discover further improvements, and the agent basically never dies beyond this point. These results are really impressive and are shown below
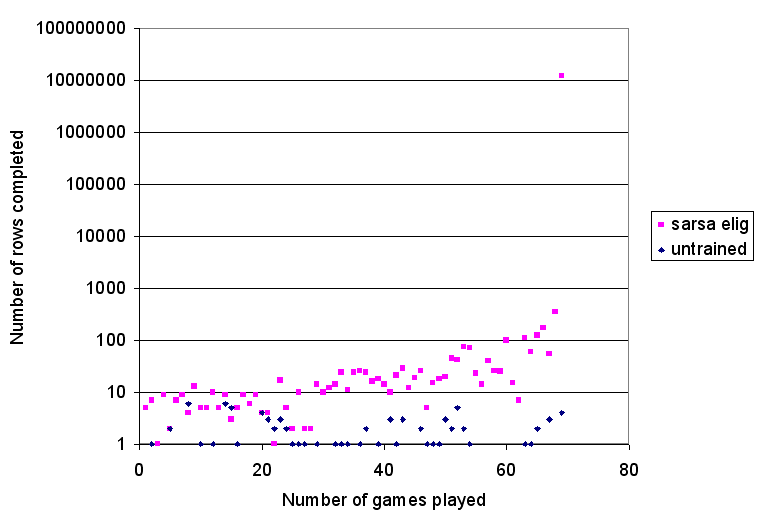
The game would not terminate on its own accord, so the agent had to be physically killed. This agent was expandable and its performance was maintained in the widening of the Tetris well.
Pros :
The final state space of the TD(0) player is 175 states big, so the player explores incredibly rapidly, and has almost nonexistent memory requirements.
The player shows evidence of :
a) learning
b) awareness. The state representation conveys enough information for him to be able to make intelligent decisions
Catches :
The player is currently using vastly simpler blocks then those traditionally employed in full tetris.
Again : Further information regarding this can be gleaned from the second powerpoint presentation available for download, under deliverables on the left hand side of this page.
Achievements
1. I have successfully managed to verify the approach to a reduced form of tetris, adopted by Stan Melax and later by Yael Bdolah & Dror Livnat.
2. I designed a reduced representtaion of the tetris state space and succesfully implemented 2 distinct agents that use it. The TD(0) learns how to complete lots of rows in a narrow well, and the Sarsa(lambda) agent learns how to play tetris, which is what I was actually hoping to achieve.
Project Timeline