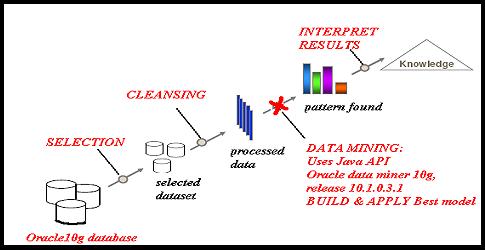

Statement of the Problem
Data mining also known as knowledge discovery, involves finding unexpected but interesting patterns within enormous amounts of data that are normally stored in databases and data warehouses. Data Mining has three major components Clustering or classification, Association Rules and Sequence Analysis which come in form of many algorithms proposed. Some of the algorithms have had better success than the others. The diagram below gives a brief idea of the data mining steps. however, there will be quite a number of techiques that will be adopted as the algorithms being investigated are kind of sofisticated in terms of determining both their efficiency and effectiveness.
|
|---|